Obsidian to published using Hazel
I wanted to create a system where I could just focus on writing and not have to worry about publishing articles to my site (and the procrastination that comes along with that). I write in Obsidian but you could do this with any editor. I set up Hazel to watch the folder where these articles are written and if the file meets certain criteria it is copied to a different folder which is then uploaded to this site. I'll cover the upload in another article but for this one I want to mainly focus on Hazel and analysing front matter.
Front matter is metadata/text that sits at the very start of a markdown file and describes the file itself and its contents. Hazel analyses any changes made to the markdown file's front matter and if it meets certain criteria it will copy the file to my blog posts folder. The front matter for this article can be seen here.

Hazel runs a node script (shown below) that checks if the front matter has a title, says published: true and for the date to be in the past.
Once the front matter matches the criteria above and hasn't been modified in the past minute Hazel assumes the article is publishable and copies it to my blog build server.
Automation flow diagram for publishing a blog post from Obsidian using Hazel
Step 1: Write.
Write a blog post, much like this one. Modify the front-matter so that it is valid. Like this:
 .
.
Step 2: Hazel.
To do this I have used a node script that uses the front-matter library to analyse the markdown file I'm editing for matching/valid front matter criteria.
Hazel setup
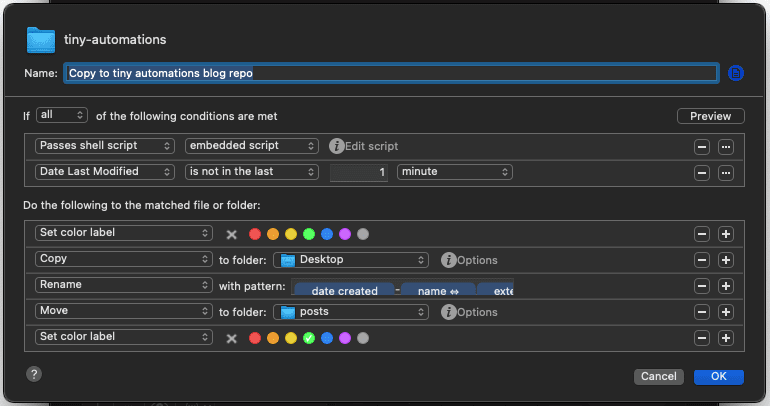
And in the embedded script I call my node script containing the front matter check. The variable passed in $1 is the matching file name.
1cd /Users/me/hazel 2output=$(node hazel-check-tiny-automations-blog-frontmatter.js $1); 3exit ${output}; 4
Node script
The console.log(0) or console.log(1) passes 0 or 1 back to the Alfred shell script above and the script exits with either a 0 (successfully matched) or a 1 (no match as yet).
1var fs = require('fs') 2var fm = require('front-matter') 3var uri = process.argv[2]; 4 5return fs.readFile(uri, 'utf8', function(err, data){ 6 if (err) throw err 7 8 var content = fm(data); 9 var isPublished = content.attributes && content.attributes.published; 10 var isDatePast = content.attributes.date && Date.parse(content.attributes.date ) < new Date(); 11 var hasTitle = content.attributes.title && true; 12 13 if(isDatePast && isPublished && hasTitle){ 14 console.log(0); 15 } else { 16 console.log(1); 17 } 18}) 19
Once the above script matches Hazel then copies the file to my posts (which is another automated build system in itself - I will cover this in another post) folder - I also do some renaming of the file so it is suitable for this blog.